「クラスター分析(クラスタリング)」とは、多数のデータを分類して、類似するデータ同士を集める手法を指します。マーケティングの現場では、市場調査や顧客情報の分析などで、クラスター分析が使われることが多いです。
クラスター分析はExcelを活用してできますが、実際に分析を行うための手順や手法など、いくつか理解しておくべきポイントがあります。適切な手法でクラスター分析を行えば、マーケティング施策の効率を最大化できるでしょう。
この記事では、クラスター分析の概要や手法について解説したうえで、実際の活用事例や注意点を詳しく紹介します。これからクラスター分析を実施してみたい方は、ぜひ参考にしてください。
サイトの成果改善でお困りではないですか?
「サイトからの問い合わせを増やしたいが、どこを改善すべきか分からない…」そんなお悩みをお抱えの方、ニュートラルワークスにご相談ください。
弊社のサイト改善コンサルティングでは、サイトのどこに課題があるかを実績豊富なプロが診断し、ビジネスに直結する改善策をご提案します。

クラスター分析とは似たもの同士を分類する手法

「クラスター分析(クラスタリング)」とは、異なる種類のものが混在している集団の中から、互いに性質が似たものを集めて「クラスター(集団)」を作るという手法です。いわば、「似たもの同士を集める」ための作業を指します。クラスター分析は、多数の情報の中から仮説をもとにして、情報の関連性を解明する「多変量解析」という手法のひとつです。
クラスター分析の対象には、人間を始めとして企業や商品、地域やイメージなど、さまざまなものが含まれます。クラスター分析は大量のデータを効率的に分類できるため、マーケティング業界では顧客の意識や行動などの特性を、分類するために活用されています。適切なセグメンテーションを行うことで、マーケティング施策を効率化できるからです。
顧客情報や市場調査の結果などを精査するときは、クラスター分析が行われることが一般的です。例えば、企業が保有している顧客リストを、顧客の属性や関心によって分類すると、それぞれの顧客に対して適切なマーケティング施策を模索しやすくなります。つまり、企業がより効率的なマーケティングを行うためには、クラスター分析が必須だということです。
クラスター分析でできること
顧客の購買行動、アンケート調査といったデータをクラスター分析し、消費者や商品を分類します。デモグラフィック(属性)情報による分類とはまた違った分類が可能です。
例えば、マーケティングでは以下のような分析時にクラスター分析が活用されます。
- 顧客層の特性分け分析
- 商品構成の分析
- 商圏の特性分析
- ブランドのポジショニング分析
クラスター分析は2種類ある

クラスター分析には、大きく分けて「階層クラスター分析」と「非階層クラスター分析」という2種類の手法があります。それぞれ性質や目的がまったく異なるため、クラスター分析を導入するときは適切な手法を選択することが重要です。本章では、それぞれの分析手法の特徴や使い分け方、メリット・デメリットについて分かりやすく解説します。
階層クラスター分析の場合
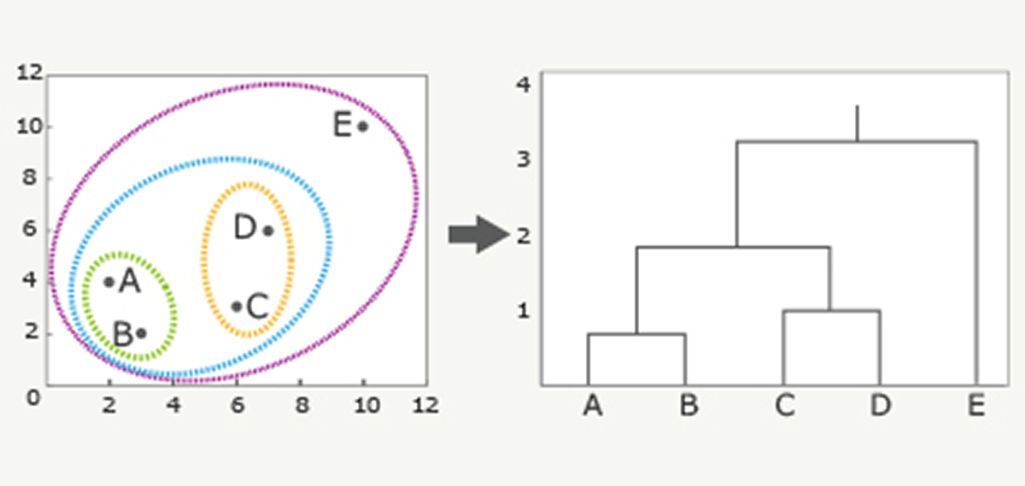
引用元:Albert Analytical technology
「階層クラスター分析」は、すべてのデータ間の「類似度」を算出した後で、一定の基準に従ってクラスターを形成していく方法です。
階層クラスター分析のメリットは、類似度が高いものから低いものへ自動的にクラスターが形成されていくため、クラスター数をあらかじめ決めておく必要がないことです。さらに、前述した階層構造図によってクラスターの構成要素が分かるため、後から任意にクラスターを分割できます。
例えば、上記の例では縦線を3本横切るように縦軸の「1」と「2」の間に線を引くと、「AB」「CD」「E」という3つのクラスターに分類できます。縦線を2本横切るように縦軸の「3」の位置で線を引くと、「ABCD」という大きなクラスターと「E」の2つのクラスターに分類できます。このように、クラスター構造を視覚化しやすいことがメリットです。
ただし、階層クラスター分析はデータ量が膨大な「ビッグデータ」の分析には向きません。計算量が多くなりすぎて実行不能になったり、分析結果の解釈が困難になったりするからです。そのため、階層クラスター分析はデータ量が比較的少ないケースに向いています。マーケティングオートメーションには不向きなので、注意が必要です。
なお、階層クラスター分析でクラスターを形成する手法には、「ウォード法」「群平均法」「最短距離法」「最長距離法」などの手法があります。最短距離法と最長距離法は計算量が少ないものの、クラスターの構造に問題が生じやすいためあまり使われません。そのため、計算量が多いものの精度が高い、ウォード法や群平均法が採用されることがほとんどです。
非階層クラスター分析の場合
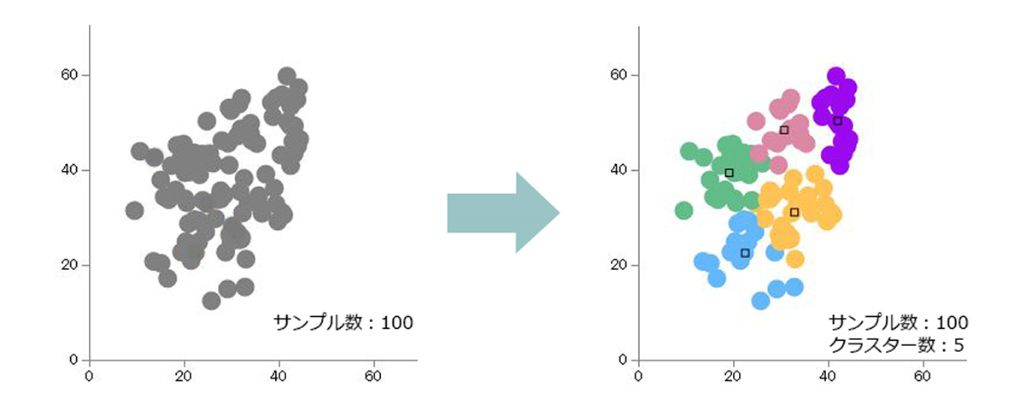
引用元:Albert Analytical technology
「非階層クラスター分析」は、あらかじめ分類するクラスター数を決めてから、互いに似た性質の要素を集めてクラスターを形成する手法です。他のクラスターとの差異と、クラスター内の類似性を強調させながら、徐々に適切なクラスター領域を形成していきます。非階層クラスター分析は階層構造を形成しないため、非階層クラスター分析と呼ばれます。
非階層クラスター分析のメリットは、計算量が少ないため膨大なデータ数を扱うことができる点です。しかも、データ数が増えてもクラスターの構造に問題が生じにくく、信頼性の高い分析結果を得られることも魅力です。そのため、前述した階層クラスター分析では困難だったビッグデータの分類も、非階層クラスター分析なら効率的に行えます。
ただし、非階層クラスター分析は分析者がクラスター数を設定する必要があり、後から任意のクラスター数に分類することはできません。最適なクラスター数を自動的に算出する手法は確立されておらず、分析者の知識や経験を頼りにしないといけない部分もあります。また、分析には「初期値」を設定する必要もあり、結果が初期値に依存することも難点です。
非階層クラスター分析でクラスターを形成する手法は、「k-means法(k平均法)」と「超体積法」などです。k-means法は、各データとクラスターの距離を計算して、最も距離が近いクラスターへ割り当て続けるというもので、一般的な形成方法です。超体積法は、データの集合を多面体と見なして、その体積を最小にしながら最適な分割法を探し出す手法です。
階層クラスター分析と非階層クラスター分析との違い
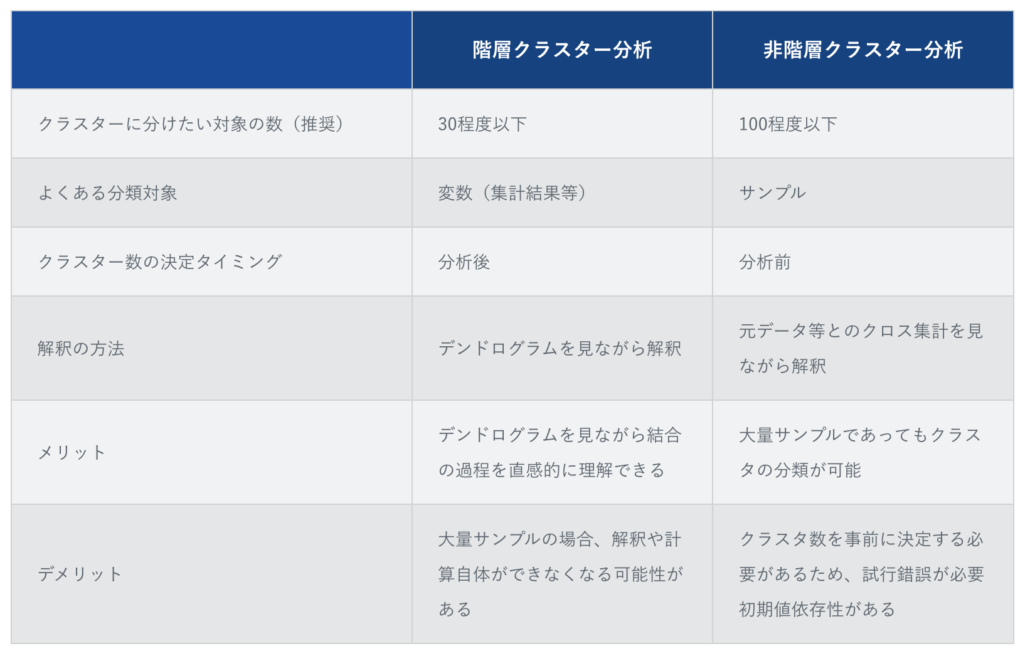
階層クラスター分析と非階層クラスター分析との違いを表にまとめています。クラスター分析を検討している場合は、どちらがマッチしているか、上記の表を見て確認するといいでしょう。
クラスター分析を行う5つの手順

クラスター分析は適切な方法で行わないと、データを効率的に分類できません。そのため、下記5つの手順を意識して、適切にクラスター分析を実施することが大切です。
- 分析目的を設定する
- クラスターの分析手法を選ぶ
- 類似度の算出方法を定義する
- クラスターの形成方法を決める
- 分析結果を活用する
本章では、クラスター分析を行うための具体的な手順とやり方を解説します。各ステップで意識することや注意点について、重要なポイントを詳しく見ていきましょう。
1. 分析目的を設定する
なぜクラスター分析を導入するのか、どういった目的で分析したいのかを考えてみましょう。分析が必要となった背景によって、採用すべき分析方法や解析手法が異なってくるからです。企業のブランディングや顧客育成、もしくはビッグデータを処理するような大規模な分析を行うなど、クラスター分析を行う目的を設定する必要があります。
また、クラスター分析を行う対象について考慮することも大切です。分析するデータの種類が曖昧であれば、求める成果を得られないかもしれません。顧客の属性や購買傾向、アンケートや市場調査のデータなど、具体的な分析対象を決めておきましょう。そもそも分析するデータがない場合は、データの収集方法から模索しないといけません。
例えば、顧客に合わせて適切なメールマガジンを配信できるようにしたい場合は、顧客属性の分析が必要になります。年齢と性別といった一般的な項目に加えて、購買傾向は顧客の関心があるテーマを示すため、特に重要性が高い要素です。購買傾向の要素を見逃している場合は、せっかくクラスター分析を行っても、意図した効果を得られないかもしれません。
2.クラスターの分析手法を選ぶ
次にクラスターの分析手法を選びましょう。前述のとおり、クラスター分析の手法は「階層クラスター分析」と「非階層クラスター分析」の2種類です。両者は性質がまったく異なるため、用途や目的に適切なものを選ばないと信頼性の高い結果を得られません。
階層クラスター分析は、クラスター数や初期値などの設定が不要で、結果を視覚化しやすいという特徴があります。しかし、データ数が多いケースでは、分析結果の信頼性が低下することが問題点です。
一方で非階層クラスター分析は、データ数が増えても分析結果の信頼性が高いため、ビッグデータの分析に最適な手法です。しかし、クラスター数や初期値などの設定が必要なため、最適な結果を得るための試行錯誤や経験が求められます。
膨大なデータを扱うことが多いマーケティング業界では、基本的には非階層クラスター分析の方が適切な傾向があると考えられます。ビッグデータを扱うマーケティングオートメーションでは、非階層クラスター分析が必須となるでしょう。
3.類似度の算出方法を定義する
採用する分析手法が決まったら「類似度」の算出方法を定義しましょう。クラスター分析は「似たもの同士」を集める手法ですが、そもそもどうやって類似度を判断するのでしょうか。クラスター分析においては、各データの「距離」を類似度と捉えます。つまり、距離が近ければ類似度が高いため、同じクラスターに分類される可能性が高いということです。
ただし、距離の定義は複数あるため、データの種類によって適切なものを採用することが重要です。私たちが普段から意識している距離は、「ユークリッド距離」と呼ばれるものです。ユークリッド距離は2点間の直線距離を指します。ユークリッド距離は分かりやすい概念ではありますが、数値だけを判断するためデータの単位が無視されることが問題です。
例えば、同じ「1」の違いであっても、年齢と身長ではデータの意味が異なります。分析対象とする要素同士に関連性がある場合も、距離の判定時に問題が生じます。顕著な例が身長と体重を分析対象とするケースです。ユークリッド距離では2つの要素の関連性を判別できないため、明らかに体形が異なっていても同じ距離だと判定されてしまうことがあります。
こうした問題を解決するために、「標準化ユークリッド距離」や「マハラノビス距離」、「マンハッタン距離」や「チェビシェフ距離」などさまざまな距離の概念があります。分析するデータに最適な距離を定義することで、クラスター分析の信頼性が高まります。専門的な分野なので不安を感じるかもしれませんが、実際の計算はソフトが行うので安心です。
「ユークリッド距離」の例
「マスクを購入する際に重視することを元に消費者を分類する」という場合に、それぞれのアンケート回答者の近さをどのように定義するのかを説明します。
まず、下記のような質問をします。

「非常に重要」を7点、「重要」を6点、以降同じように、最後「まったく重要ではない」を1点で換算します。3名にアンケートしたところ、下記のようなデータになりました。
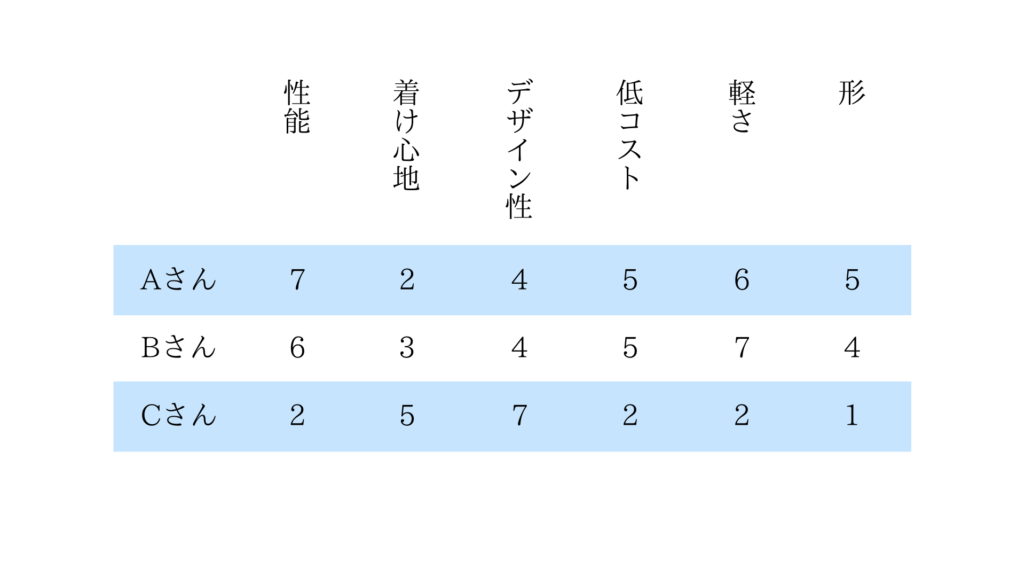
ここから以下のことが分かります。
- 「性能」は、AさんとBさんは 7-6=1 の違い
- 「着け心地」は、AさんとBさんは 2-3=-1 の違い
- 「デザイン性」は、AさんとBさんは 4-4=0 の違い
- 「低コスト」は、AさんとBさんは 5-5=0 の違い
- 「軽さ」は、AさんとBさんは 6-7=-1 の違い
- 「形」は、AさんとBさんは 5-4=1 の違い
それぞれの項目における差の二乗和の平方根をAさんとBさんの距離として計算すると、以下のようになります。
- AさんとBさんの距離は2.000
- AさんとCさんの距離は9.165
- BさんとCさんの距離は8.485
これをグラフにすると直感的にも分かりやすくなります。
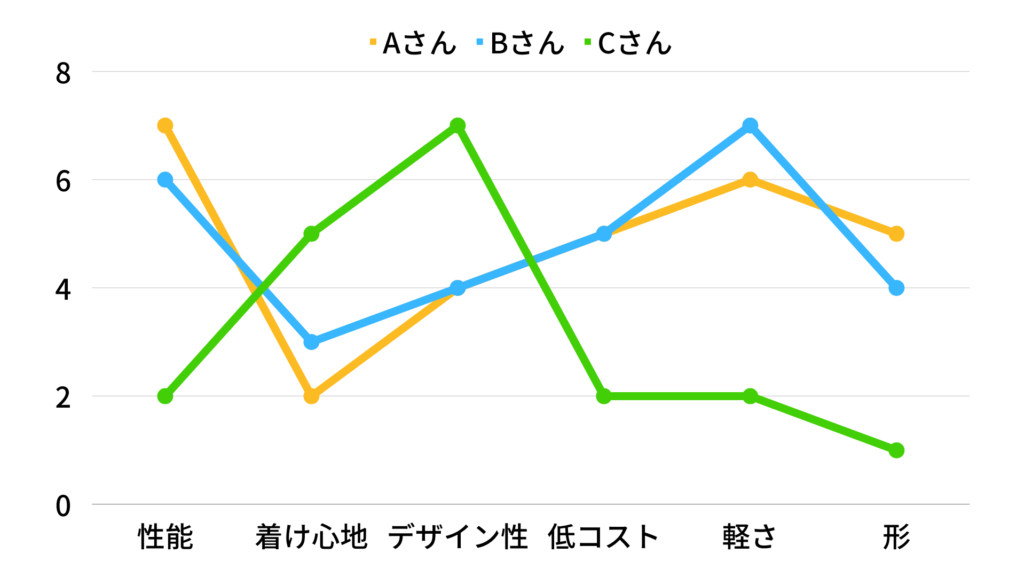
上のグラフを見て分かるように、AさんとBさんは近いことが直感的に理解できるでしょう。
4.クラスターの形成方法を決める
分析手法や距離(類似度)の定義ができたら、クラスターの形成方法を決めましょう。先ほども触れたように、階層クラスター分析と非階層クラスター分析には、それぞれ複数のクラスター形成方法があります。どの方法を選択するかによって、クラスターが形成される順番やバランスなどが大きく異なります。主要なクラスターの形成方法は下記のとおりです。
| 分析手法 | クラスターの形成方法 | 概要 |
|---|---|---|
| 階層クラスター分析 (類似するデータ同士をまとめていくことで、クラスターを形成する) |
ウォード法 | クラスターの重心と、クラスター内の各サンプルとの距離を考慮して形成していく |
| 重心法 | クラスターの重心からの距離を基準に形成していく | |
| 最短距離法(最近隣法) | 距離が近いものから順に形成していく | |
| 最長距離法(最遠隣法) | 距離が遠いものから順に形成していく | |
| 群平均法 | 各クラスター同士で、データの距離の均を基準に形成していく | |
| 非階層クラスター分析 (類似するデータ同士が同じクラスターに属するように、全体を分割していく) |
k-means法(k平均法) | 各データとクラスターの距離を考慮して、最も距離が近いクラスターへ割り当てる |
| 超体積法 | データで構成される多面体の体積が最小になるように、全体を分割していく |
専門的な知識が必要になる分野なので、非常に分かりづらいかもしれません。しかし、基本的には階層クラスター分析では「ウォード法」を、非階層クラスター分析では「k-means法(k平均法)」を採用すれば問題ありません。これらの形成方法はクラスターに問題が生じづらいため、安定して信頼性の高い結果を得られるからです。
5.分析結果を活用する
無事にクラスター分析が成功して結果が出たとしても、それはあくまで各データがどのクラスターに属するかを示すものに過ぎません。形成されたクラスターは分析者が解釈して、具体的な情報として活用する必要があります。その解釈に問題があれば、クラスター分析の効果を得られません。
例えば、食料品販売のメーカーが顧客の購買傾向を分析するケースを考えてみましょう。分析の結果クラスターが6つ形成された場合、それぞれのデータ傾向から「ヘルシー層」「スイーツ層」「ガッツリ層」などのように、分類を解釈する必要があります。
本来は「ヘルシー層」であるべきクラスターを「ガッツリ層」と解釈すると、その後のマーケティング施策が誤ったものになってしまいます。クラスター分析はあくまで「箱」にデータを振り分けるだけであって、その箱に具体的な「ラベル」を付けるのは分析者自身です。正しい解釈を行った後は、各クラスターに合うマーケティング施策を実行しましょう。
類似する顧客が集まっていてターゲットは絞られているため、これまでより容易なものとなるはずです。
クラスター分析の具体的な活用事例

クラスター分析の種類や手順を確認したところで、下記3つのケースにおける具体的な活用事例について見ていきましょう。
- アンケートや市場調査などのデータ分析を行う
- BtoBにおけるOne to Oneマーケティングに活用する
- 顧客情報をもとにメルマガやDMの配信を効率化する
各ケースでクラスター分析がどのように役立つのか、メリットや意識すべきポイントなども含めて分かりやすく解説します。
アンケートや市場調査などのデータ分析を行う
アンケートや市場調査などで取得したデータを解析するために、クラスター分析が効果的です。調査を実施するだけでは、質問ごとの回答とそれぞれの傾向しか分かりません。例えば、自社のサービスについて顧客がどのように考えているか、どの広告施策の集客効果が高かったのかという点です。
もちろん、こうした情報も有益ではありますが、マーケティング施策の効果を高めるためには不十分です。質問ごとではなく顧客ごとに、さらには似たような顧客集団ごとの傾向をつかむ必要があります。そこで、クラスター分析を実施することにより、顧客単体のデータから顧客をグループに分類することができます。
顧客ごとのデータしかなければ、効果的なマーケティング施策を実行することは困難です。画一的な手法では顧客のニーズに応えられませんし、顧客ごとに施策を立案するのは現実的ではありません。顧客をある程度グループ化して、グループごとの傾向に応じた施策を実行するのがマーケティングの基本です。
これまで解説してきたように、クラスター分析は大量のデータを分類して、似た傾向を持つもの同士を集めるための手法です。形成されたクラスターを正確に解釈すれば、グループに属する顧客が抱えているニーズが分かります。グループごとのユーザーに合わせアプローチを行えば、マーケティング施策が成功しやすくなるでしょう。
BtoBにおけるOne to Oneマーケティングに活用する
BtoBにおいては、これまで以上に「One to Oneマーケティング」の重要性が増しています。One to Oneマーケティングは「顧客一人ひとりに合わせたマーケティング」のことで、画一的ではなく個々のニーズを満たす施策を指します。なぜなら、顧客はインターネットを活用して、自分でいくらでも情報を得られるからです。
顧客に自社を認知してもらい、意思決定の過程で自社との契約に導くためには、顧客が抱えるニーズと合致する有益な情報を提供しないといけません。前述したように、すべての顧客に合わせたマーケティング施策の立案は困難です。そこで、顧客を分類して傾向を予測するために、クラスター分析が必要となります。
顧客がどのタイプのクラスターに属しているかが分かれば、自社が過去に関わった同種の顧客に関するノウハウを活かして、マーケティング施策を実行できます。例えば、顧客が必要とする情報を予測してメルマガやDMを送付したり、キャンペーンを開催したりするなどです。また、クラスター分析は下記のように「STP分析」にも有効です。
| 頭文字 | 意味 | 概要 |
|---|---|---|
| S | Segmentation(セグメンテーション) | ターゲット顧客層を決定するために、市場を細分化すること |
| T | Targeting(ターゲティング) | セグメントの中から、どの顧客をターゲットとするか決めること |
| P | Positioning(ポジショニング) | 他社との差別化を図るために、市場での自社の地位を決めること |
セグメンテーションには、年齢や性別、興味や関心などの変数をもとに行いますが、変数の決定が困難な場合にクラスター分析が有効です。多数の顧客の中から自社が狙うべき顧客層を決めるターゲティングでは、クラスター分析によるグループ化で有益な情報を得られます。競合他社と自社の製品を比較するポジショニングでも、クラスター分析が役立ちます。
 STP分析とは?目的と分析方法、事例をわかりやすく解説
売れるマーケティング戦略、販売戦略を立てるときに欠かせないマーケティングフレームワークの1つがSTP分析です。STP分析の基本から分析方法、注意点、STP分析での成功事例をご紹介します。
STP分析とは?目的と分析方法、事例をわかりやすく解説
売れるマーケティング戦略、販売戦略を立てるときに欠かせないマーケティングフレームワークの1つがSTP分析です。STP分析の基本から分析方法、注意点、STP分析での成功事例をご紹介します。
顧客情報をもとにメルマガやDM配信を効率化する
クラスター分析は、メルマガやDMの効果を高めるためにも役立ちます。前述のとおり、現在は顧客がいつでも情報を入手できる環境が整っているため、顧客のニーズに合致しないメルマガやDMを配信しても意味がありません。多くの場合は無視されて、より有益な情報を提供する他社に顧客が流れてしまうでしょう。
顧客がどのような情報を求めているかが分かれば、有意義なメルマガやDMを送付することができます。そのために役立つのが顧客情報ですが、多数のデータから顧客の傾向をつかむのは困難です。クラスター分析を行えば、自社が保有している顧客情報を分析して、一定の傾向を持つユーザー同士でクラスターを形成できます。
他の施策でも解説したように、クラスターごとの特徴を理解することさえできれば、後はグループに合わせたメルマガやDMを配信するだけです。あらかじめクラスターを定義してノウハウを蓄積しておけば、新しい顧客を獲得したときも迅速に施策の実行へ移れます。また、他の業種やプロジェクトにも活かせるでしょう。
クラスター分析をするときの4つの注意点

クラスター分析を実施するときは、下記4つの点に注意することが重要です。あらかじめ必ず確認しておきましょう。
- 事前に分析する目的と仮説を明確にする
- 必ずしも客観的な結果を得られるとは言えない
- 他の分析手法と併用することも必要になる
- Excelだけでは分析できないこともある
せっかくクラスター分析を行っても、分析結果の扱い方に問題があると、マーケティング施策を効率化できません。
事前に分析する目的と仮説を明確にする
クラスター分析を行う前に、なぜ分析を行うのかという目的や、結果を予測するための仮説を立てておくことが重要です。目的が明確でなければ、分析の対象とすべきデータや類似性の定義も分からないため、正確な結果を得ることはできません。
また、クラスター分析はあくまで、データをクラスターに分類するためのものです。結果が出た後のクラスターの取り扱いは、分析者に委ねられています。適切な方法で情報を解釈しなければ、まったく的外れなマーケティング施策を行ってしまいかねません。
事前にある程度の予測を立てておかなければ、分析結果を有効活用することが難しくなります。形成されるであろうクラスターはいくつあるのか、どのような傾向でクラスターが分類されているかなどの仮説は、あらかじめ立てておくようにしましょう。
必ずしも客観的な結果を得られるとはいえない
クラスター分析の結果は、必ずしも「客観的」とはいえないことにも注意が必要です。なぜなら、分析によって得られたクラスターの傾向をどのように解釈するかという点や、マーケティング施策への活用法については、すべて分析者に委ねられているからです。
クラスターの解釈では、どうしても主観が入ってしまうリスクがあります。例えば、「この顧客層にはこういう傾向があるに違いない」という先入観や、「こんな顧客層に自社製品を使ってもらいたい」という願望などです。
また、マーケティング業界で採用されることが多い非階層クラスター分析は、最初にクラスター数と初期値を決める必要があります。あらかじめ期待した結果に、実際の結果が左右されてしまうことがあるため、クラスター分析の結果は絶対視しないようにしましょう。
他の分析手法と併用することも必要になる
繰り返しになりますが、クラスター分析はあくまでデータを分類するためのものです。「自社の顧客にはこのような傾向があります」もしくは「このようなマーケティング施策を実行しましょう」というような、具体的な方向性を示してくれるものではありません。
どのような規則性や因果関係によってクラスターが形成されたかは、クラスター分析の結果を見ただけでは判断できません。クラスターを独自に解釈する必要がありますし、そこで主観も入るため、クラスター分析だけで施策の改善を実行することは困難です。
したがって、クラスター分析だけに依存するのではなく、回帰分析や相関分析など他の分析手法も併用することが重要です。これらの手法はいずれも、データの関連性を明らかにするためのもので、マーケティング施策を具体的に立案するために極めて効果的です。
Excelだけでは分析できないこともある
クラスター分析は表計算ソフトの「Excel」で行うことができますが、単体で高度な情報を得ることはまず困難です。クラスター分析には複雑な計算が必要なため、Excelに搭載されている標準機能では、満足なパフォーマンスを発揮できないからです。
どのようなクラスター分析を行う場合でも、Excelのアドインである「エクセル統計」は導入しておきましょう。エクセル統計は階層型と非階層型どちらにも対応しており、「ユークリッド距離」や「ウォード法」など、算出方法やクラスターの形成方法も設定できます。
ただし、より専門的で精度の高いクラスター分析を行うのであれば、エクセル統計ではなく「R」「SPSS」「JMP」など専門の統計分析ソフトが必要です。専門的な知識やコストが要求されますが、マーケティング施策の効果を最大化するためにぜひ導入してみましょう。
クラスター分析のまとめ

クラスター分析を行えば、無数のデータを分類して、似たような傾向を持つグループごとにまとめることができます。クラスター分析には、「階層クラスター分析」と「非階層クラスター分析」の2種類のものがあり、大量のデータを扱うことが多いマーケティング業界では、信頼性がデータ数に左右されづらい非階層クラスターを採用することが一般的です。
クラスター分析を実施する際は、分析する目的を明確化したうえで分析手法を決め、類似度の算出方法やクラスターの形成方法を選択します。ユークリッド距離やウォード法など、さまざまな専門用語が登場しますが、基本的には統計分析ソフトの説明どおりに使えば問題ありません。分析後はクラスターの分類を解釈して、施策の改善に活用しましょう。
サイトの成果改善でお困りではないですか?
「サイトからの問い合わせを増やしたいが、どこを改善すべきか分からない…」そんなお悩みをお抱えの方、ニュートラルワークスにご相談ください。
弊社のサイト改善コンサルティングでは、サイトのどこに課題があるかを実績豊富なプロが診断し、ビジネスに直結する改善策をご提案します。
クラスター分析のよくあるご質問
- クラスター分析とは?
-
「クラスター分析(クラスタリング)」とは、異なる種類のものが混在している集団の中から、互いに性質が似たものを集めて「クラスター(集団)」を作るという手法です。いわば、「似たもの同士を集める」ための作業を指します。クラスター分析は、多数の情報の中から仮説をもとにして、情報の関連性を解明する「多変量解析」という手法のひとつです。
- クラスター分析でできることは?
-
顧客の購買行動、アンケート調査といったデータをクラスター分析し、消費者や商品を分類します。デモグラフィック(属性)情報による分類とはまた違った分類が可能です。
- クラスター分析の種類は?
-
クラスター分析には、大きく分けて「階層クラスター分析」と「非階層クラスター分析」という2種類の手法があります。