
この記事のポイント
この記事でおさえておきたいポイントは以下です。
-
クローラーとは何か
-
クローラーとは、検索エンジンがウェブサイトを自動的に巡回し、コンテンツを収集・インデックスするためのプログラムです。収集した情報は検索エンジンのデータベースに保存され、これにより検索結果が生成されます。
-
クローラーの巡回頻度を上げる方法
-
クローラーの巡回頻度を上げるには、定期的なコンテンツ更新、内部リンクの最適化、高品質な外部リンクの獲得、XMLサイトマップの提出が効果的です。
-
クローラーがWebサイトを巡回しているかどうかの確認方法
-
検索エンジンに「site:巡回を確認ページのURL」を打ち込み、検索結果にページが表示されるか確認する方法と、Google search consoleにログインして上部の検索バーに調べたいページのURLを貼り付け、「URLはGoogleに登録されています」と表示されるか確認する方法があります。
検索エンジンがインターネット上で情報を収集し、ユーザーに最新かつ関連性の高い検索結果を提供するためには、クローラーが不可欠です。
この記事では、クローラーの基本的な機能と役割、そしてWebサイトをクローラーフレンドリーにするための方法についてわかりやすく解説します。
SEO対策をおこなう上でクローラーを理解することは重要なポイントですのでぜひ参考にしてください。
<無料>資料ダウンロード
【サイト運営者必見】SEO対策成功事例集
実例から学ぶ、急成長を遂げたストーリーが見られる!
目次
クローラーとは

クローラーとは、Web上の情報を自動的に収集するプログラムのことです。
検索エンジンがインターネット上のWebページをインデックスする際に使用され、新しいコンテンツや更新されたコンテンツを定期的にチェックします。
クローラーはWebのリンク構造を辿りながら動作し、収集した情報を検索エンジンのデータベースに保存します。
このプロセスによって、最新のWebページ情報をユーザーに提供できるという仕組みです。
クローラーの役割と重要性
・Googlebot(Google)
・Bingbot(マイクロソフト/Bing)
・Baiduspider(バイドゥ)
など
クローラーは、インターネット上のWebページを収集し、検索結果の品質と正確性を保つ役割を果たします。
クローラーが効率的に動作することで、検索エンジンは最新の情報を迅速にインデックスし、ユーザーに関連性の高い検索結果を提供できます。
したがって、Webサイト運営者はクローラーがスムーズにアクセスできるようサイトを最適化することが重要です。
クローラーにやさしいWebサイトの設計が鍵
クローラーがスムーズにアクセスできるWebサイトにするには、コンテンツを容易に見つけられる構造にする必要があります。
具体的には、明確なナビゲーション、ロジカルなURL構造、適切な内部リンク、高速なページロード時間などが含まれます。
また、重複コンテンツの排除、適切なタイトルタグとメタ記述の使用も重要です。これらの要素はクローラーの効率を高め、検索エンジンのインデックスに正しく表示されることを確実にします。
クローラーの基本的な動作と仕組み

繰り返しになりますが、クローラーは検索エンジンのために、Webサイトを自動的に巡回し、情報を収集するプログラムです。
その基本的な動作プロセスは、まずWebサイトのrobots.txtファイルを読み込むことから始まります。
robots.txtファイルには、クローラーに対する指示が含まれており、どのページをクロールすべきか、または避けるべきかが定義されています。
クローラーは許可されたページにアクセスし、HTMLコード、テキスト、リンクなどの情報を収集します。
収集したデータは、検索エンジンのインデックスに追加され、検索結果のランキングに使用されます。
また、クローラーはページに含まれるリンクを辿り、新しいページへと移動します。このプロセスはWeb全体を網羅するまで繰り返され、検索エンジンは常に最新の情報を保持します。
クローラーの巡回頻度を上げる方法

クローラーの巡回頻度を上げる方法には、いくつかのポイントがあります。
新しいコンテンツの追加
定期的に新しいコンテンツを追加することは、クローラーがWebサイトを再訪する重要な理由となります。
ブログの更新や製品情報の更新など、新鮮なコンテンツを提供することでクローラーの注目を引きます。
サイトマップの更新と送信
XMLサイトマップを使用し、新しいページや更新されたコンテンツを定期的に検索エンジンに通知します。
Google Search ConsoleやBing Webmaster Toolsなどのツールを使用してサイトマップを直接送信できます。
 Googleインデックスとは?インデックスされない場合の登録方法も解説
Googleインデックスとは、ウェブページがGoogleのデータベースに登録され検索結果に表示される状態を指します。この記事では、仕組みやインデックスされない場合の対処法について解説しています。
Googleインデックスとは?インデックスされない場合の登録方法も解説
Googleインデックスとは、ウェブページがGoogleのデータベースに登録され検索結果に表示される状態を指します。この記事では、仕組みやインデックスされない場合の対処法について解説しています。
サイトのパフォーマンスの最適化
ページのロード時間を短縮し、ユーザーエクスペリエンスを向上させることで、クローラーの効率を高めます。画像の圧縮、キャッシュの活用、レスポンシブデザインの実装などが有効です。
内部リンクの強化
Webサイト内のページ間で適切な内部リンクを設定すると、クローラーがサイト内をスムーズに移動し、新しいコンテンツを発見しやすくなります。
 内部リンクとは?SEO効果や、効果的な設置方法を解説
内部リンクは、ウェブサイト内のページ同士をつなぐリンクで、ユーザーの利便性向上やSEO効果に重要な役割を果たします。この記事では、内部リンクの基本概念、SEOへの効果、設置方法について解説しています。
内部リンクとは?SEO効果や、効果的な設置方法を解説
内部リンクは、ウェブサイト内のページ同士をつなぐリンクで、ユーザーの利便性向上やSEO効果に重要な役割を果たします。この記事では、内部リンクの基本概念、SEOへの効果、設置方法について解説しています。
ソーシャルメディアとの連携
ソーシャルメディアでコンテンツを共有し、外部からのリンクを増やすことで、クローラーの注目を集めやすくなります。
SNS上での活動は、Webサイトへの新たなトラフィックを生み出し、これがクローラーの訪問頻度を高める要因にもなります。
エラーの修正
404エラーなどのクロールエラーを修正し、Webサイトの健全性を保ちます。エラーが少ないサイトは、クローラーにとってアクセスしやすく、頻繁に訪れる対象となります。
クローラーがWebサイトを巡回しているかどうかの確認方法

クローラーが実際にサイトを巡回しているのかどうか確認するには、以下2つの方法があります。
- site:検索で確認する
- Google Search Consoleで確認する
site:検索で確認する
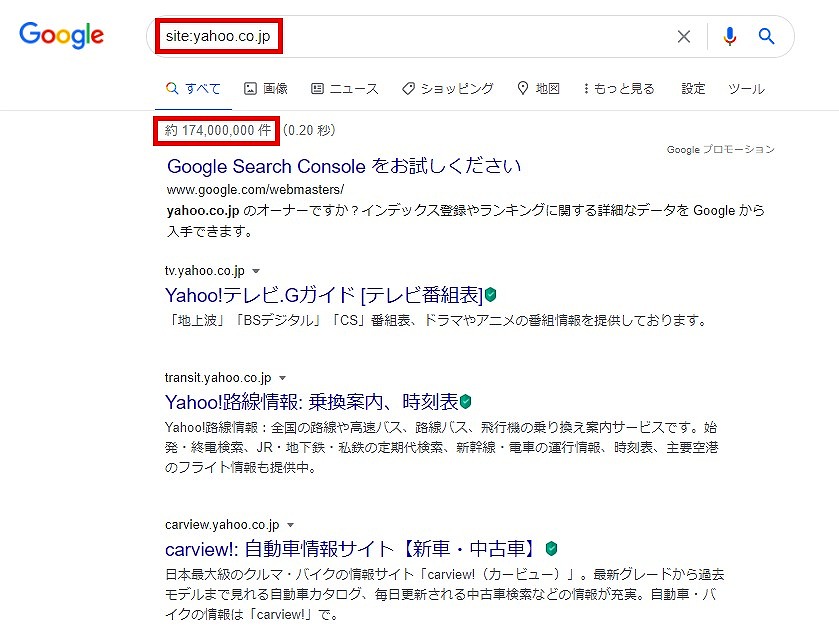
検索エンジンに「site:巡回を確認ページのURL」と打ち込み、検索結果にページが表示されるか確認してみましょう。検索結果にページが表示されたら、クローラーが正常に巡回していることになります。
Google Search Consoleで確認する
Google search consoleを使ったインデックスの確認手順は次のとおりです。
1.Google search consoleにログイン
2.上部の検索バーに、調べたいページのURLを貼り付け
3.「URLはGoogleに登録されています」と表示されるか確認する
クローラーが巡回していないようであれば、インデックスをリクエストしてください。
クローラーに関するまとめ

クローラーはWeb上の情報を自動的に収集し、検索エンジンのデータベースに保存するための重要なプログラムです。検索エンジンの効率的な動作を支え、ユーザーに最新の情報を提供する役割を果たします。
Webサイト運営者は、クローラーにとってアクセスしやすいサイト構造を整えることが重要であり、明確なナビゲーションやロジカルなURL構造、適切な内部リンクなどが含まれます。
また、クローラーの巡回頻度を高めるためには、新しいコンテンツの追加、サイトマップの更新と送信、サイトのパフォーマンス最適化などが有効です。
最終的に、クローラーの巡回状況を確認することで、Webサイトが検索エンジンに適切にインデックスされているかを把握できます。
<無料>資料ダウンロード
【基礎編】サイト運営者様必見!SEO対策入門ガイド
〜SEO対策のポイントやメリット・デメリットを分かりやすく解説!〜



































